
Recensione del ContainerDay 2019: c’eravamo anche noi!
Un giorno alla principale conferenza italiana dedicata alle tecnologie container
Di Kevin Borghi
Venerdì 8 novembre a Bologna si è tenuto, presso l’Hotel Savoia Regency, il ContainerDay 2019, dedicato al tema container, che sta prendendo sempre più piede tra sviluppatori, sistemisti, DevOps engineer, project manager e altre figure del mondo IT. Ecco la mia recensione.
La conferenza aveva un prezzo molto accessibile che comprendeva anche pranzo e due coffee break. Nel corso della giornata si sono avvicendati vari speaker, italiani ed esteri. Vi propongo le mie valutazioni personali sui talk ai quali ho partecipato.
Preambolo: cosa sono i container?
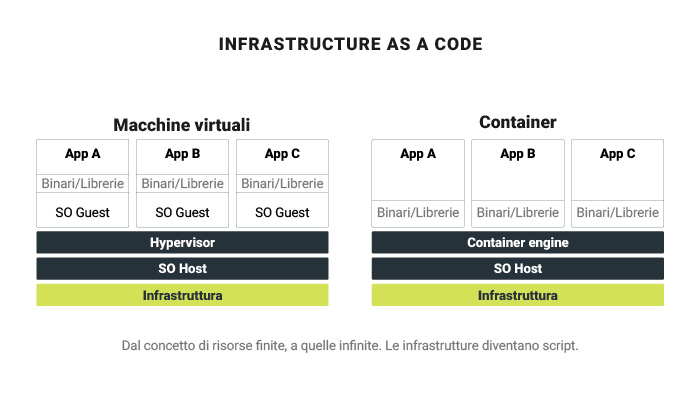
Le macchine virtuali tradizionali (VM) consentono la virtualizzazione dell’infrastruttura informatica, mentre i container rendono possibile quella delle applicazioni software. A differenza delle macchine virtuali, i container utilizzano il sistema operativo (SO) dell’host, anziché fornire il proprio.
Dato che non includono sistemi operativi completi, i container richiedono risorse di elaborazione minime e risultano rapidi e semplici da installare. Tale efficienza ne consente la distribuzione in cluster, con container individuali che racchiudono componenti singoli di applicazioni complesse. Grazie a questa separazione, gli sviluppatori possono aggiornare i componenti applicativi singolarmente, senza la necessità di modificare l’intera applicazione.
La Unix Way vista da un DevOps
Fabio Mora ha riassunto la storia e l’evoluzione delle tecnologie informatiche partendo dai primi calcolatori, passando per schede perforate, Unix, Linux, virtual machines per arrivare agli attualissimi container. Se vuoi puoi leggere le sue slides.
Parallelamente si è parlato dello smantellare le applicazioni monolitiche, tipiche della precedente generazione, in microservizi tenendo un approccio KISS. Cito l’intro del talk per approfondire il termine KISS.
«Con l’acronimo KISS (Keep It Simple and Stupid) si evoca un modo di fare software antico: la UNIX Way. […] si tratta piuttosto di una filosofia progenitrice del movimento DevOps. Declinata oggi nel mondo Linux da migliaia di tecnici e organizzazioni, che include assunti come modularità, semplicità, composizione e chiarezza nel fare. Tutto evolve portandosi dietro principi solidi e al tempo stesso pronti al cambiare: dai modelli open-source ai flussi Git, dalla gestione dei pacchetti ai container, dalle infrastrutture a risorse finite agli orchestratori del cloud; fino a mescolare le definizioni stesse di sistema operativo e applicazione tra user-space e kernel-space»
Le sfide attualmente sono: trovare uno standard per le Infrastructure as Code (IaC) – un papabile standard può essere Google Anthos – e applicare la filosofia dell’invisible infrastructure.
Provisioning di container Docker usando Ansible: the good, the bad and the ugly
Serena Lorenzini ha illustrato alcuni esempi di una meno nota applicazione di Ansible: usarlo al posto del classico docker compose per fare configurazione e provisioning di container Docker. La sintassi YAML li rende molto simili ma Ansible ha dalla sua la migliore gestione delle variabili, la possibilità di inserire task di test, un inventory per il dump delle informazioni dell’host e la possibilità di eseguire comandi. Riporto che Ansible deve essere utilizzato per la configurazione una tantum e, per il configuration management, procedere con Chef e Puppet è meglio. Infine ha raccontato come è possibile impiegare Molecule per il test driven development.
Se vuoi puoi leggere le sue slides.
State of Windows Containers, how to modernise your IT for Windows Applications
Paolo Tonin ha fornito una visione globale dell’evoluzione dello sviluppo dei container su Windows e alcuni approcci su come affrontare l’adozione di questa tecnologia per modernizzare l’infrastruttura IT (puoi leggere le sue slide). Ha parlato della partnership tra Microsoft e Docker che ha portato all’inclusione di Docker EE all’interno di Windows Server 2016 e successivi per poi offrire delle nozioni riguardo all’utilizzo di container con Windows Container o Hyper-V Container. Infine ha impartito qualche consiglio, dato dalla sua esperienza DevOps su AWS e Azure, su quali servizi ha senso e conviene portare in container:
- Evitare: Active Directory, SQL Server, utilizzo di grafica, hardware specifico e networking avanzato.
- Accettabile: servizi Powershell.
- Ottimale: webserver.
Deploy e monitoring di un RabbitMQ cluster su Kubernetes
In questo coinvolgente talk Gabriele Santomaggio ha mostrato passo passo il deploy dal vivo (coraggioso 😜) di un RabbitMQ Cluster su K8s con Helm e Charts. Ha analizzato le problematiche legate alla scalabilità del cluster come, ad esempio, gestire la persistenza dei dati ed il monitoring con Prometheus e Grafana. Se vuoi puoi leggere le sue slides.
Multi container applications with Docker Compose
Paolo Ferretti, developer advocate, ha illustrato come usare Docker Compose per riprodurre fedelmente su una macchina locale gli stack di produzione. Ha fatto vedere esempi pratici e dato consigli su come usare Docker Compose durante il deploy in produzione o stage e sia per testing. Un consiglio utile è come ripulire un container tra un test e l’altro per evitare di avere residui da operazioni precedenti: docker-compose down --rmi local --volumes --remove-orphans
(puoi leggere la documentazione o, più in generale, le sue slides).
Cloud Native for the Edge Computing
Appena dopo pranzo Adriano Pezzuto ha esposto come è possibile utilizzare un approccio cloud native nell’edge computing. Ricordo che per cloud native si intende il modo in cui viene eseguito e studiato un servizio e non dove viene eseguito, mentre con edge computing vogliamo definire la parte dell’IT più in prossimità all’ambiente fisico.
Si è parlato del perché l’edge computing è così importante. Principalmente i motivi sono: esecuzione in tempo reale, possibilità di lavorare anche offline, ottimizza lo scambio dati e lo storage dei dati ed è orientato alla sicurezza e alla privacy. Un esempio di ambienti di utilizzo possono essere le windfarm, le aziende e le piattaforme petrolifere.
Infine Adriano è passato all’Edge K8s, Rancher K3s, microK8s chiudendo col concetto di Edge Abstraction con l’utilizzo dei virtual-kubelet, argomenti interessanti ma lontani dalla mia esperienza e che sicuramente approfondirò.
Se vuoi puoi leggere le sue slides.
Containerization of parallel MPI and accelerated applications on HPC systems
Giuseppa Muscianisi ha raccontato la sua esperienza con i container in un ambiente molto specifico: High Performance Computing, abbreviato in HPC. Si tratta di una nicchia ma i container possono essere utilizzati anche qui. Ha elencato le possibili alternative e le relative motivazioni per cui hanno scelto Singularity:
- Encapsulation of the environment
- Containers are image based
- No user contextual changes or root escalation allowed
- No root owned daemon processes
Successivamente ha mostrato i dati relativi ai test per capire se e quanto i container influiscono sulle prestazioni in ambiente HPC. La risposta a questa domanda è che i container non influiscono sulle prestazioni e ad avvalorare questa risposta c’erano i risultati di test con Quantum Espresso, tipico carico CPU e network bound, sia Tensorflow, carico GPU intensive con necessità di accedere ad hardware specifico come la GPU. Se vuoi puoi leggere le sue slides.
Kubeflow - Data Science on Steroids
Sascha Grunert ha presentato Kubeflow: il machine learning toolkit per Kubernetes. Kubeflow è un progetto dedicato a rendere semplici, portatili e scalabili le implementazioni dei flussi di lavoro di machine learning su Kubernetes e Sascha, durante il talk, ha mostrato un esempio di funzionalità di Kubeflow, come la generazione e la gestione di server Jupyter e la creazione da zero delle nostre pipeline di machine learning.
Anche questo argomento è troppo specifico per le mie conoscenze quindi per ulteriori informazioni vi consiglio di approfondirlo sul sito di Kubeflow o sulle sue slides.
Writing Cloud-Native Applications for Kubernetes
Martino Fornasa ha illustrato le linee guida che ogni sviluppatore software moderno dovrebbe conoscere e seguire per essere eseguita al meglio sfruttando le caratteristiche dei container. Ha parlato di twelve-factor app, che è una metodologia di sviluppo orientata alla costruzione di applicazioni software-as-a-service che segue i seguenti dettami:
- un formato dichiarativo per l’automazione della dichiarazione;
- interfacciamento in modo trasparente con il sistema operativo sottostante;
- adatte allo sviluppo sulle più recenti cloud platform, minimizzano la divergenza tra sviluppo e produzione rendendo più semplice il continuos deployment;
- possono scalare agilmente senza importanti modifiche ai processi e ai tool.
Ha quindi parlato di questioni sempre più attuali e di concetti di sviluppo che condivido pienamente, in particolare è emerso come sia necessario e importante comunicare chiaramente le caratteristiche che deve avere un’applicazione cloud native.
Se vuoi puoi leggere le sue slides.
Conclusioni
Nonostante il buon numero di partecipanti e la sala al completo, l’organizzazione è stata pressoché impeccabile. Tempi rispettati, nessun intoppo particolare, cibo e caffè abbondanti, argomenti variegati: tutto si è svolto al meglio con un bel clima di collaborazione e apertura.
Da alcune sessioni mi aspettavo un approfondimento tecnico maggiore, ma è comprensibile che non sia stato possibile, sia per il tempo ristretto sia per la vastità del tema, che ha davvero tante applicazioni come ad esempio HPC, pipeline CI/CD e di produzione.
Per un novizio dei container come me, l’occasione è stata comunque utilissima per iniziare a toccare con mano gli strumenti, la filosofia e le sue applicazioni nel mondo reale. Continuerò senz’altro ad approfondire le mie conoscenze in materia, confidando che questo sia stato solo il primo degli eventi del settore ai quali parteciperò.
Nel frattempo sto già puntando un nuovo evento organizzato dal GrUSP: Incontro DevOps il 5-6 marzo 2019.
Tutte le informazioni sull’evento potete trovarle sul sito ufficiale. Le slide dei talk, quando disponibili, vengono caricate su joind.in. I video della conferenza saranno pubblicati entro qualche settimana sui canali Vimeo e YouTube del GrUSP.
Fonti
Grusp
ContainerDay 2019
Kubeflow
The Twelve Factor App
Syslabs.io
Doker documentation
joindin - ContainerDay 2019