
Building a Simple Parallel and Controlled Task Runner in JavaScript
Building a simple background runner for file uploading in JavaScript
By Calson Chiatiah
It’s 6.30AM and Doe is enjoying the comments on X (formerly Twitter) on his recent post about his new app. He’s not done blushing from all the nice things people are saying about his app when out of the blues, all focus switches to Anim’s post blasting his app.
"It’s too slow when uploading a folder, and when it’s happening I just can’t do any other thing on the app. That’s if you are lucky enough that nothing fails, otherwise, you would have to restart ‘’, Amin laments over X. “Oh, yeah, I know why that’s happening and I have a TODO task to improve this process”, Doe murmurs to himself. So here’s what happened, as Doe reflects, the files are being uploaded to a storage system that accepts one file per request. There’s no way to upload multiple files in a single request. So Doe was picking up 4 files at a time and firing in a batch using Promise.all. The one mistake Doe made is not to have made this a background process so Anim can continue to enjoy the app while the upload is happening.
Looking at the logs, Doe discovers Anim tried uploading 50 files and there were files as large as 2.5GB. Once it was uploading a 2.5GB file, it had to await until the Promise.all resolved. So it could not pick up any new files even though only 1 file was in progress. When a folder was encountered, an endpoint had to be called for some computation to happen before any files in that folder could be uploaded. If this folder endpoint returned an error, then the whole process had to stop.
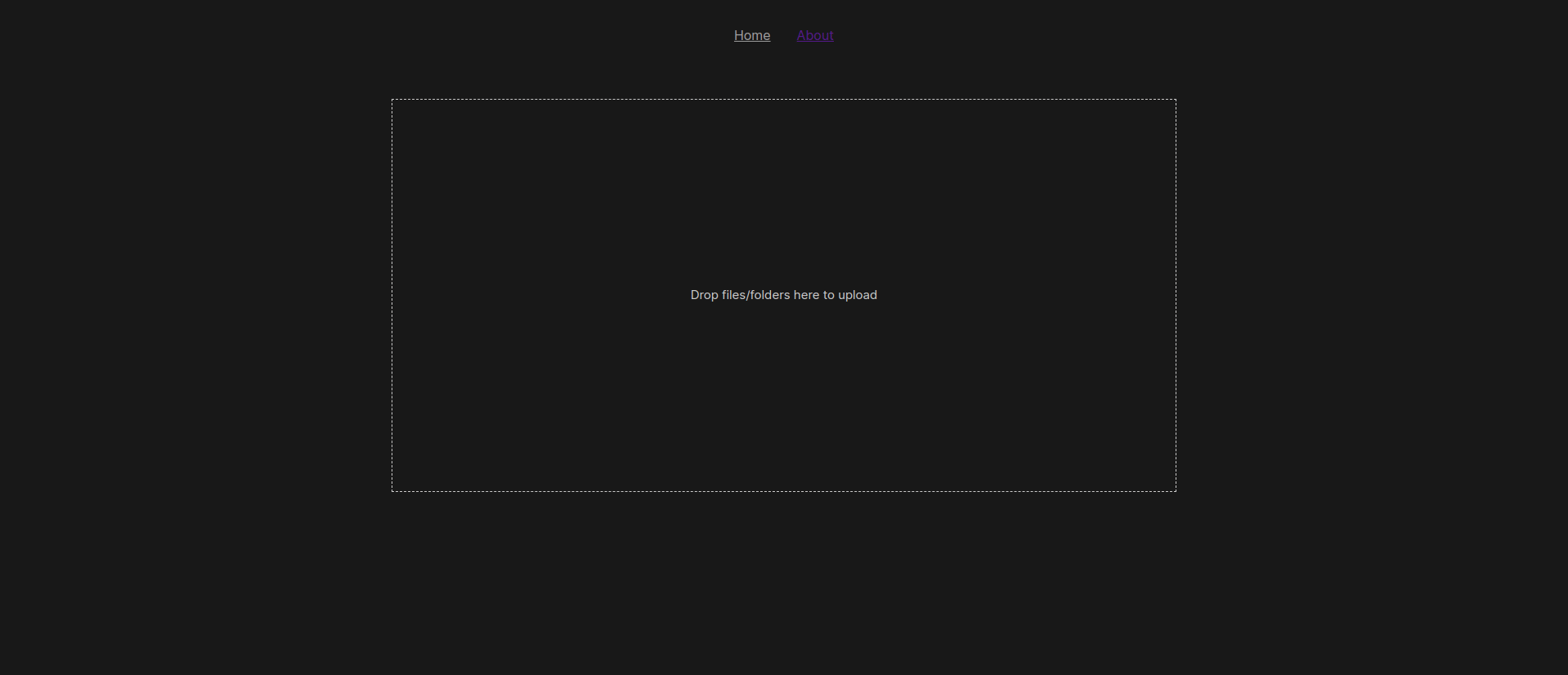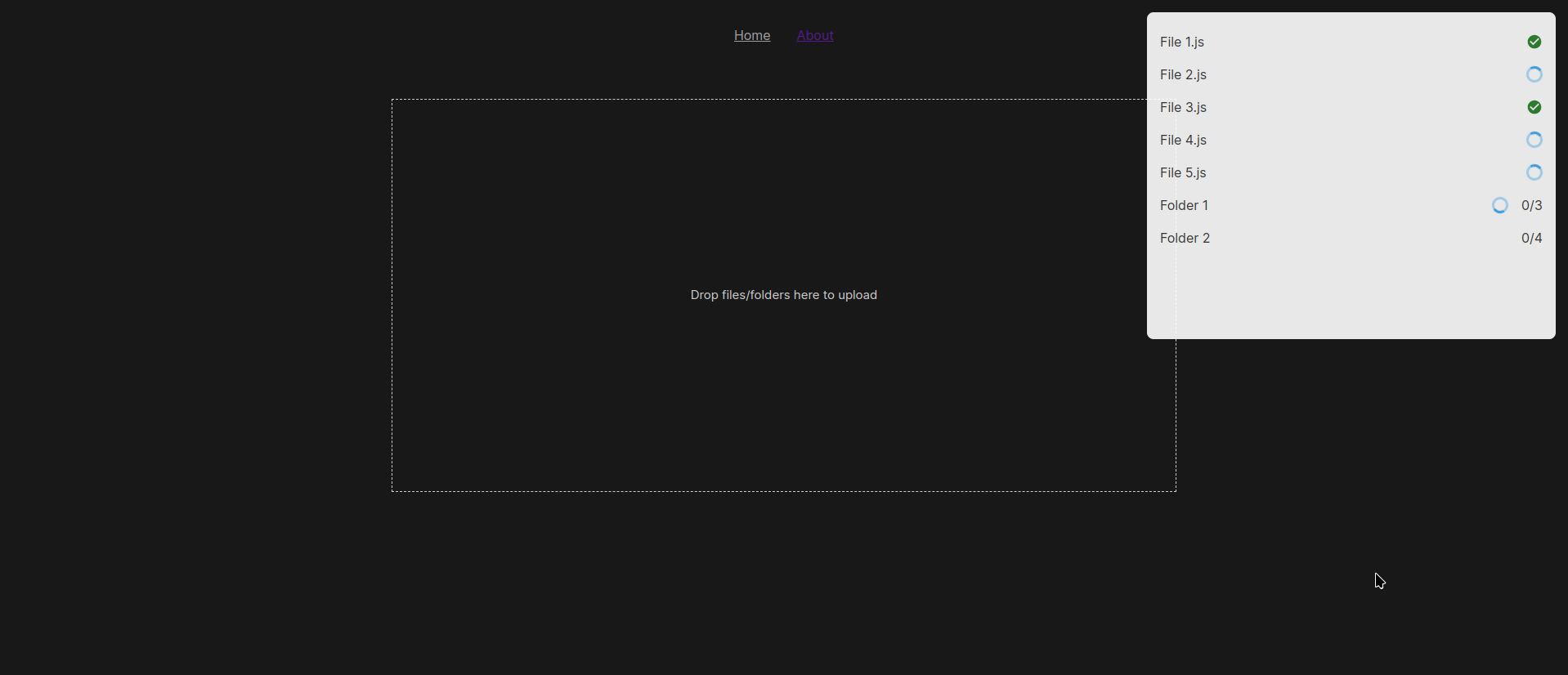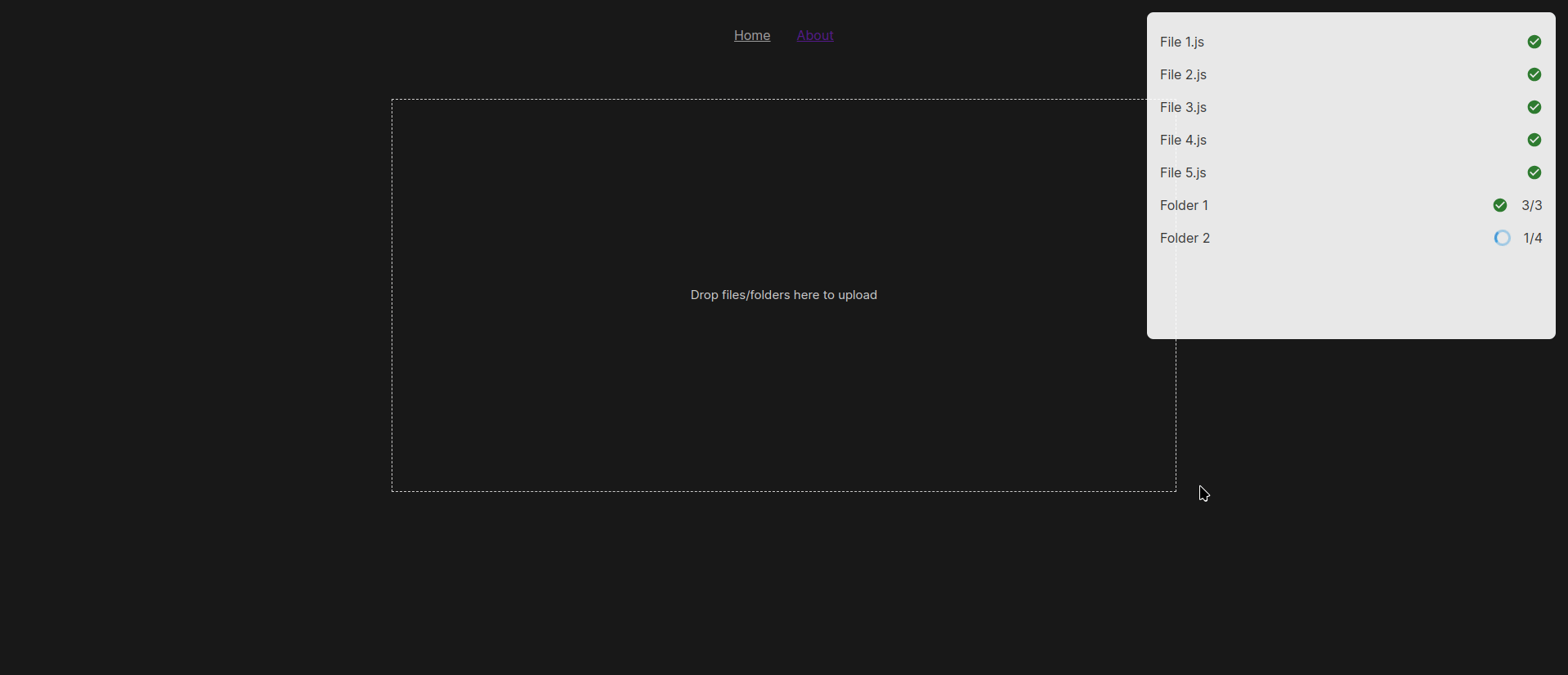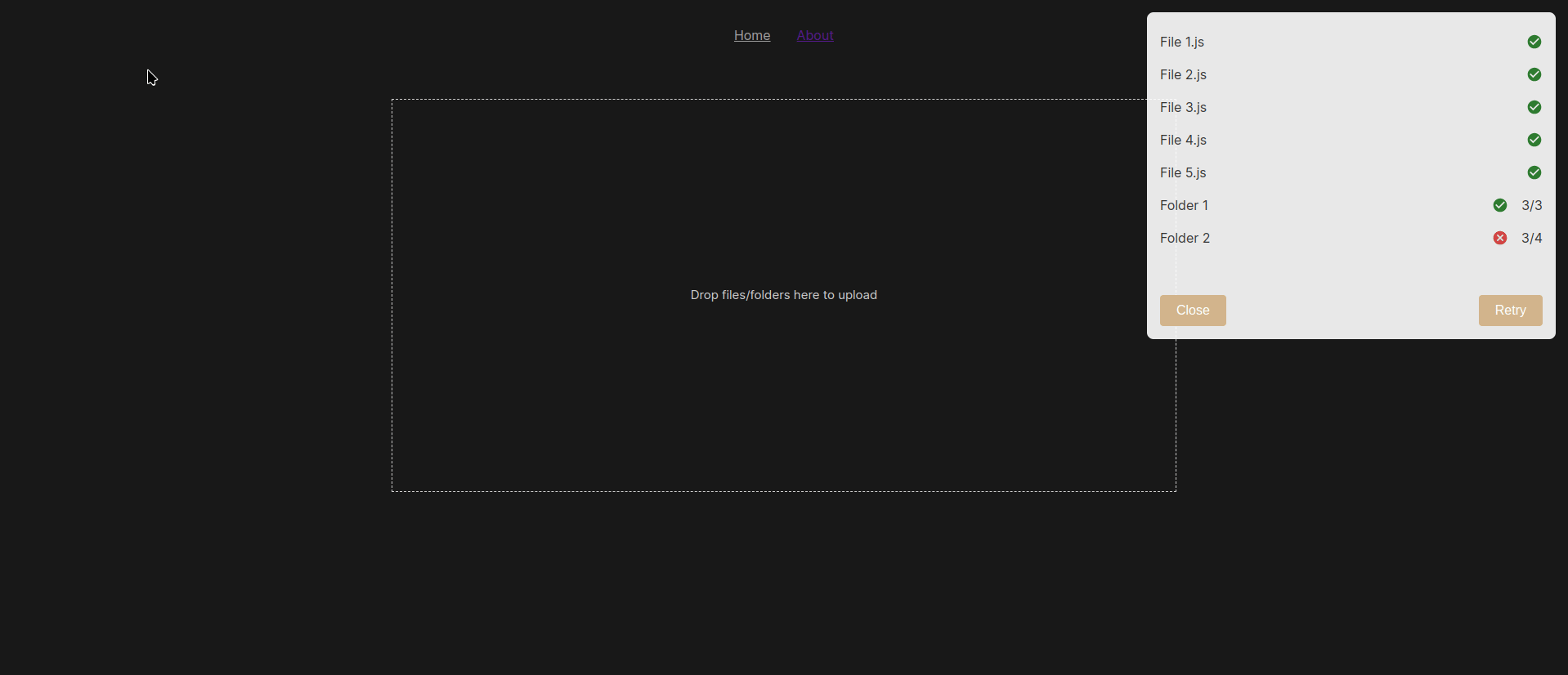
In this blog post, we will build a background job processor that can address some of these issues. The background processor will be able to pick up jobs from a queue and execute them. It will execute a fixed number of jobs in parallel. And once a job completes, it will pick up new ones and execute them ensuring it always maintains the number of running jobs to the fixed number. It also ensures that when blocking jobs are being run, no new jobs can be run until the blocking jobs are completed and moved out of the running queue. Equally, failed jobs will be saved in a failed jobs queue and retried on demand.
Implementation
You can check out the code for this blog post here. Because we want to easily display the results of the background processor, I’ll use the Vue framework. But the processor logic is not Vue specific. It can be easily adapted to any other framework.
Let’s start off by declaring the queues to store the processor state.
export function useJobProcessor<T extends Job>({
onBeforeStart,
onCleanUp,
blockJobFn,
nonBlockJobFn,
}: {
onBeforeStart?: (jobs: T[]) => void;
onCleanUp?: () => void;
blockJobFn?: (job: T) => Promise<unknown>;
nonBlockJobFn?: (job: T) => Promise<unknown>;
}) {
const runningJobs = ref<{ index: number; entry: Job }[]>([]);
const completedJobs = ref<Job[]>([]);
const readyJobs = ref<Job[]>([]);
const failedJobs = ref<Job[]>([]);
let isBlocked = false;
function run() {
// ...
}
// ...
}
Let’s pretend not to notice the useJobProcessor parameters. We will revisit them later. Let’s focus on the job queues in the meantime:
readyJobs: it stores the list of jobs that are ready for processing. Jobs are continuously being picked fromreadyJobsand added torunningJobsfor processing.runningJobs: it stores the list of jobs that are currently being processed. Once a job completes, it is removed from therunningJobslist whether or not it was successful.completedJobs: it stores the list of jobs that have completed successfully.failedJobs: it stores the list of jobs that failed to complete successfully.isBlocked: it stores a boolean value that indicates whether the processor is currently blocked from processing new jobs. This is used to prevent new jobs from being picked from thereadyJobsqueue and moved into therunningJobsqueue while a blocking job is being processed.
The general idea is to pick up jobs from the readyJobs queue and add them to the runningJobs queue. Once a job completes, it is removed from the runningJobs queue and added to the completedJobs queue. Before picking up a new job, we have to ensure that the isBlocked flag is set to false. If it is set to true, then no new jobs will be started. We need to do this continuously until there are no more jobs in the readyJobs queue or another condition is met.
Now that we have that settled, let’s look at the other conditions that influence the processor’s behaviour. Declare the following constants outside of the useJobProcessor function.
// We can make this configurable to improve the API
const MAX_NUMBER_OF_PARALLEL_JOBS = 4;
const MAX_NUMBER_OF_FAILED_JOBS = 10;
const JOB_PICKUP_INTERVAL = 500;
const FAIL_ON_BLOCKING_JOB_ERROR = true;
The MAX_NUMBER_OF_PARALLEL_JOBS constant determines the maximum number of jobs that can be running at the same time. If there are up to MAX_NUMBER_OF_PARALLEL_JOBS jobs in the runningJobs queue, then no new jobs will be picked up. Once the runningJobs queue is full, the processor will block new jobs from being picked up. Whenever a running job completes, it is removed from the runningJobs queue, freeing up a slot so that a new job can be picked. We will see how the other two constants are used shortly.
Before we implement the core logic of the processor, let’s make it start and run in a continuous loop. Let’s implement the start method that bootstraps the core logic of the processor.
async function start(jobs?: T[], isRetrying?: boolean) {
if (!isRetrying && (isRunning.value || readyJobs.value.length !== 0)) {
console.error(
'Cannot start an upload process while another is not completed'
);
return;
}
if (jobs) {
setJobs(jobs);
}
isRunning.value = true;
return new Promise((resolve, reject) => {
const interval = setInterval(function () {
try {
run(interval, resolve);
} catch (error) {
clearInterval(interval);
reject(error);
}
}, JOB_PICKUP_INTERVAL);
})
.then(() => {
if (completedJobs.value.length !== 0) {
// Do something when completed
}
if (failedJobs.value.length !== 0) {
// Do something when failed
} else {
// Do something when successful
cleanUp();
}
})
.catch(() => {
cleanUp();
})
.finally(() => {
isRunning.value = false;
});
}
The start method receives an optional array of jobs to be processed. It starts off by ensuring that the processor is not already running and that there are no jobs being processed. The line setJobs(jobs) adds the jobs to the readyJobs queue while the isTrying flag informs it that it is a retry.
Jobs are run continuously using the setInterval global method. It calls the run method every JOB_PICKUP_INTERVAL milliseconds in a promise. The run method is responsible for stopping the interval when it is done processing. It will do so by clearing the interval and resolving the promise. This is the reason why it takes interval and resolve as arguments.
At this point, we can go ahead and implement the run method which is responsible for handling the core logic of the processor. We will look at its implementation in two parts.
Part 1: Out of the rabbit hole at last
In this section, we look at how the processor eventually resolves and stops being called eventually. This has to be handled diligently, otherwise, the processor will never stop running.
function run(interval: ReturnType<typeof setInterval>, resolve: (value: unknown) => void) {
if (readyJobs.value.length === 0) {
if (runningJobs.value.length === 0) {
clearInterval(interval)
resolve(true)
}
// All jobs should have been processed. We will return to wait for running ones to complete
return
}
// If there are too many failed jobs then do not process more. This ensures running jobs conclude before resolving
if (failedJobs.value.length >= MAX_NUMBER_OF_FAILED_JOBS) {
if (runningJobs.value.length === 0) {
clearInterval(interval)
resolve(true)
}
// There are already too many failed jobs, so we return in order not to start new ones.
return
}
// The failed directory should most likely be at the end of the list. This is because directory
// creation is blocking and no new jobs should have been added from when the directory creation
// started and failed. So the only jobs that could also be found after it in the list are those
// that were already running and failed after it failed.
// We therefore loop in reverse order because we can easily find them at the end of the list
// than at the start.
if (FAIL_ON_BLOCKING_JOB_ERROR) {
for (let index = failedJobs.value.length - 1; index >= 0; index--) {
// If there's a directory that failed to create then wait for current running tasks to complete and exit
if (failedJobs.value[index].isBlocking) {
if (runningJobs.value.length === 0) {
clearInterval(interval)
return resolve(true)
}
// Returning here ensures that we do not try to read more entries until the current running ones have completed.
return
}
}
}
if (isBlocked) {
return
}
if (MAX_NUMBER_OF_PARALLEL_JOBS - runningJobs.value.length < 1) {
return
}
// ... more code to be added later
Let’s start off by considering two scenarios.
- There are no more jobs but some jobs are still running: Once it detects this, it does not continue further. It returns until it is called after
JOB_PICKUP_INTERVALto check again if the running jobs are completed. - There are no more jobs and no running jobs: Once it detects this, then it means everything is done. So it stops the interval and resolves the promise.
It then proceeds to do similar checks but this time to ensure that we do not pick more than MAX_NUMBER_OF_PARALLEL_JOBS jobs. It also ensures that if a blocking job fails and it is configured to stop on blocking job failures, it no longer tries to pick more jobs. Instead, it waits until the current running jobs have completed and then it resolves.
The lines below ensure that if a blocking job is running, then no new jobs will be run and it maintains the number of parallel jobs to MAX_NUMBER_OF_PARALLEL_JOBS.
if (isBlocked) {
return;
}
if (MAX_NUMBER_OF_PARALLEL_JOBS - runningJobs.value.length < 1) {
return;
}
Part 2: When in the rabbit hole
In this section, we look at how new jobs are picked up and processed. Let’s do this by completing the run method from Part 1.
// ...
// It's okay to load more jobs at this point.
// -1 because we pick the last job
const indexOfPoppedFile = readyJobs.value.length - 1
const currentlyRunningJob = readyJobs.value.pop()
if (currentlyRunningJob?.isBlocking && indexOfPoppedFile > -1) {
isBlocked = true
runningJobs.value.push({ index: indexOfPoppedFile, entry: currentlyRunningJob })
createBlockingJob(currentlyRunningJob)
.then((result) => {
// ... e.g. do something with the result
completedJobs.value.push(currentlyRunningJob)
})
.catch((error) => {
currentlyRunningJob.error = {
message: 'Network Error',
fullMessage: '',
exception: error
}
// Put back the job into the failed jobs stack because an error occurred. Because failed jobs are saved, we can retry the operation
// We may also want to indicate that the failure is not one that can be retried.
failedJobs.value.push(currentlyRunningJob)
console.error(error)
})
.finally(() => {
isBlocked = false
// Irrespective of whether the directory creation failed or succeeded, we remove the directory from the running state
// If jobs are left running, then the runner will not know when to stop
// Once a condition to stop the runner is met, the runner waits until all running jobs are completed
const runningIndex = runningJobs.value.findIndex(
({ index }) => index === indexOfPoppedFile
)
if (runningIndex !== -1) {
runningJobs.value.splice(runningIndex, 1)
}
})
}
if (currentlyRunningJob?.isNonBlocking) {
runningJobs.value.push({ index: indexOfPoppedFile, entry: currentlyRunningJob })
createNonBlockingJob(currentlyRunningJob)
.then((result) => {
// ... e.g. do something with the result
completedJobs.value.push(currentlyRunningJob)
})
.catch((error) => {
// Write the error message
currentlyRunningJob.error = {
message: 'Network Error',
fullMessage: '',
exception: error
}
// Mark the file as failed, so that it can be retried
failedJobs.value.push(currentlyRunningJob)
})
.finally(() => {
// Always remove the file from the running state whether it failed or succeeded
const runningIndex = runningJobs.value.findIndex(
({ index }) => index === indexOfPoppedFile
)
if (runningIndex !== -1) {
runningJobs.value.splice(runningIndex, 1)
}
})
}
}
In this section, we pick up new jobs from the readyJobs queue and process them. When a new job is picked, it is pushed to the runningJobs queue and once it completes or fails, it is removed. Removing the job provides a slot for new jobs to be pushed in. The runBlockingJob and runNonBlocking functions are responsible for processing the blocking and non-blocking jobs respectively.
The life cycle hooks
The useJobProcessor function takes an object representing the life cycle hooks.
onBeforeStart: This hook is called right before the processor starts.onCleanUp: This hook is called right after the processor completes and is responsible for clearing up the state.blockJobFn: This hook is called to run a blocking job. It receives as argument the current blocking job being processed.nonBlockJobFn: This hook is called to run a non-blocking job. It receives as argument the current non-blocking job being processed. In Doe’s case, it might be a request to upload a file to S3.
With the above job processor, Doe can now provide the quality users’ of his platform deserve. We have skipped some implementation details of the processor, the Repo has the complete working processor. The repo demonstrates a possible use case of the processor in task scheduling. Clone the repo and test it out.
Imagine your app with a task runner or other great features that tackle the unique challenges of your projects. We can build a custom solution to meet the specific needs of your application. Contact us now!